Perché usare la geostatistica e che vantaggi offre il software ArcGIS su questo fronte?
La geostatistica è lo strumento che consente di stimare il valore incognito di punti su una superficie sulla base di valori misurati. Non solo: consente di conoscere l’incertezza dei punti così stimati, o la probabilità di superamento di un dato valore “critico”. Così, se si possiedono (ad esempio) dati puntuali di concentrazione di ozono su un’area, è possibile spazializzarli su un’intera superficie in maniera da conoscere le concentrazioni nelle zone prive di misurazioni, o creare una mappa delle zone “a rischio” (concentrazioni oltre un certo valore tollerabile).
Il Geostatistical Analyst di ArcGIS for Desktop è un insieme completo di strumenti che guida gli utenti passo passo verso la creazione della mappa (superficie) ottimale, e fornisce anche procedure standard affidabili che possono essere utilizzate per produrre una mappa preliminare in poco tempo.
La barra degli strumenti Geostatistical Analyst si presenta in maniera semplice e permette un’analisi dei dati spaziali completa e intuitiva. In particolare, in questo articolo verrà presentato lo strumento Geostatistical Wizard, che offre vari metodi di interpolazione fra i quali scegliere (deterministici o gostatistici) per ottenere una mappa di previsioni. La scelta del metodo da utilizzare e dei vari parametri è facilitata dalla presenza di un help nella finestra del Geostatistical Wizard che si aggiorna ogniqualvolta si clicca su una voce configurabile/selezionabile. Inoltre, il processo che porta alla creazione di una mappa è suddiviso in passaggi che guidano l’utente passo passo verso il completamento dell’operazione. Ogni scelta influenzerà il numero di passaggi successivi e soprattutto le tipologie di scelte configurabili.
L’esempio riportato nel presente articolo è preso dal Tutorial dell’Help di ArcGIS. E’ possibile installare il materiale necessario dall’ArcGIS for Desktop Tutorial Data setup, oppure provare a cercarlo nel percorso di default se è già stato installato (in genere “C:\arcgis\ArcTutor”).
In breve, vedremo come utilizzare il Kriging ordinario per calcolare una mappa di stime di concentrazioni di ozono da punti misurati per il territorio della California. Anzitutto, una premessa che può essere utile: il Kriging ha varie tipologie (es. ordinario, universale, semplice, ecc.), ed è l’unico metodo di interpolazione geostatistico presente. Gli altri (IDW, RBF, Spline), sono metodi deterministici che utilizzano formule matematiche per il calcolo della superficie, ma che non coinvolgono la statistica (non danno una stima degli errori!). La scelta fra le varie tipologie di Kriging dipende molto dalla presenza di eventuali trend nel dataset. Se è stato ritrovato un trend nei dati (ad es. con lo strumento Explore Data–>Trend Analysis, vedi esercizio 2 del Tutorial), ed è stato rimosso adeguatamente, i risultati ottenuti con le diverse tipologie saranno molto simili fra loro.
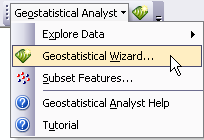
Il principio di base della geostatistica è: due punti vicini nello spazio (o nel tempo), sono più simili fra loro di due punti lontani nello spazio (o nel tempo, prima legge della geografia di Tobler). ArcGIS calcola il semivariogramma dei dati (che si basa proprio su questo principio), per calcolare la superficie da stimare, assieme all’incertezza delle stime stesse. Per ottenere una superficie in maniera rapida è possibile selezionare il metodo Kriging nella prima finestra del Geostatistical Wizard, e accettare (facendo click su Next) tutti i passaggi, non modificando le impostazioni di default proposte da ArcGIS. In pochi secondi sarà possibile ottenere una mappa preliminare della stima di concentrazioni di ozono per tutta la California.
Conoscere i propri dati, e comprendere le scelte dei vari passaggi del Geostatistical Wizard è indispensabile per produrre delle mappe affidabili. Alcuni consigli prima di procedere alla modellazione (spazializzazione) dei propri dati:
- Studiarne la distribuzione spaziale: per funzionare adeguatamente, molti metodi richiedono che il dato abbia una distribuzione normale (non è il caso del Kriging). Gli strumenti utili a individuare il tipo di distribuzione sono Histogram e Normal QQplot, entrambi selezionabili dal menu a tendina della voce Explore Data.
- Individuazione dei trend: definito come una rappresentazione “funzionale” dei dati spaziali, deve essere rimosso con attenzione (se si riconosce la ragione intrinseca della sua esistenza nel dato) prima di procedere all’interpolazione. Lo strumento per individuare un trend è il Trend Analysis (sempre in Explore Data). Nel caso dell’esempio in esame, esiste un trend decrescente di concentrazioni di ozono dal centro della California verso Nord/Sud, Est/Ovest, dovuto alla presenza di montagne, di venti dalla costa verso il centro dello Stato, e dagli insediamenti urbani fra la costa e le montagne.
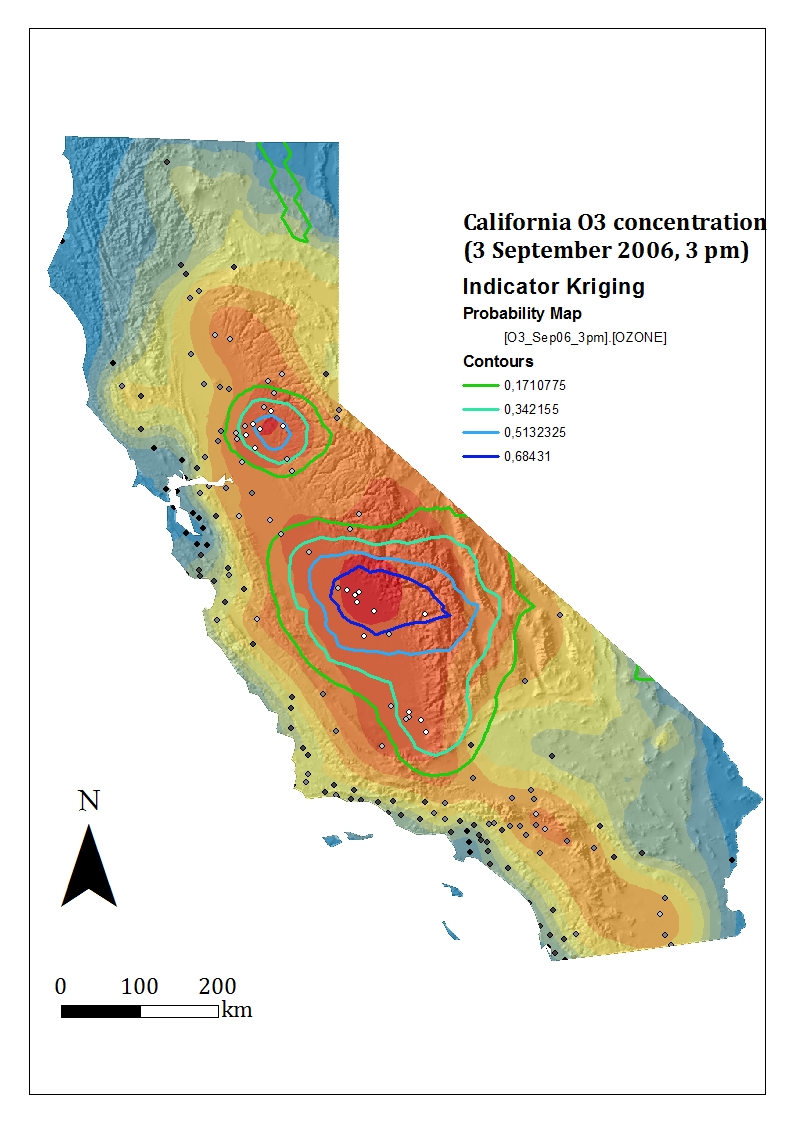
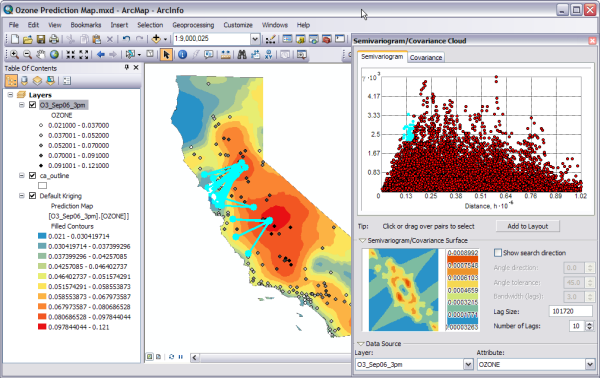
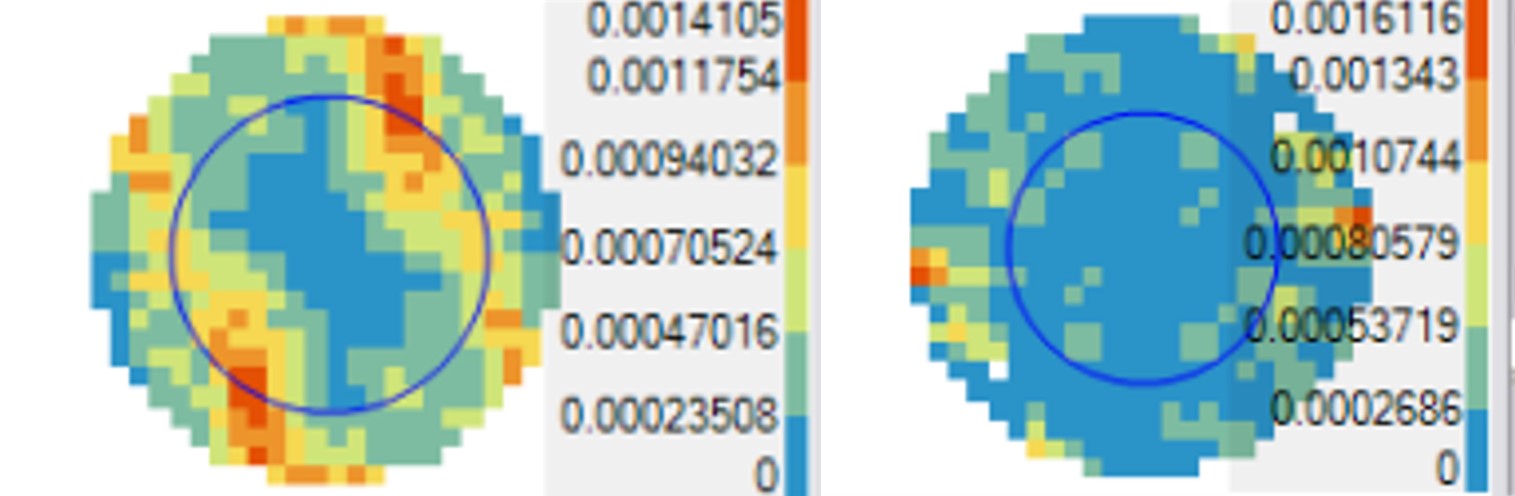
- Presenza di influenze direzionali: guardando il semivariogramma (da Geostatistical Analyst scegliere Explore Data e poi Semivariogram/Covariance Cloud), è possibile studiare l’autocorrelazione dei dati e selezionare i punti con valori elevati. Questi potrebbero rappresentare errori di misura, oppure (come nel caso in esame, vedi prossima figura), indicare una direzione in cui l’autocorrelazione è persa in maniera più rapida (Est/Ovest, per il motivo di cui al punto 2).
Conoscere i dettagli del proprio set di dati significa scegliere un metodo di interpolazione in maniera più obiettiva, e ottenere risultati verosimilmente migliori. Ad esempio, per spazializzare la concentrazione di ozono in California (in riferimento al tutorial di ArcGIS), si può scegliere di fare un Kriging ordinario rimuovendo il trend presente nei dati con il secondo passaggio del Geostatistical Wizard (nel caso in esempio il trend è una polinomiale di secondo grado, e quindi l’ordine del trend da rimuovere sarà “secondo”). Rimuovendo il trend il modello lavora sui cosiddetti “residui” e di conseguenza è possibile analizzare la variabilità locale del dato anziché quella globale. Analogamente a quanto visto in fase di analisi, il semivariogramma (passaggio 4 di 6) può essere utilizzato per ricercare un’ulteriore influenza direzionale nei residui, ed eventualmente impostare il parametro Anisotropy su True, per tenerne conto. La differenza di influenza direzionale prima e dopo aver rimosso il trend è evidenziata nei due grafici sotto.
Il penultimo passaggio del Geostatistical Analyst (Searching Neighborhood) consente di impostare un’area di ricerca (forma, ampiezza e direzione) da usare per definire quali punti osservati (misurati) verranno utilizzati per stimare ciascun punto non misurato. Se i dati osservati sono sparsi, si consiglia di dividere l’area di ricerca in più quadranti in modo da evitare che i punti osservati considerati siano concentrati in una piccola porzione dell’area stessa.
L’ultima fase è quella di cross-validazione, che consente di valutare la bontà del modello prima di produrre la mappa. In sostanza, tramite una procedura chiamata “jack-knife”, si esclude dall’interpolazione una singola osservazione per volta, si effettua il confronto tra il valore interpolato e il valore noto escluso, e si applica questo procedimento via via a tutti i punti. In questo modo è possibile valutare l’errore del modello, ovvero la differenza fra i valori stimati e quelli osservati. La finestra di cross-validazione mostra anche interessanti grafici e statistiche pivotali utili nella valutazione del funzionamento del modello.
In conclusione, è possibile produrre la mappa (superficie) desiderata, interrogarla, e eventualmente confrontarla con altre mappe prodotte con altri metodi di interpolazione (tasto destro sulla mappa che si vuole confrontare nella Table of Content–>Comapare…). Vengono visualizzati i diagrammi di cross-validazione delle mappe da confrontare e , in sostanza, la mappa che ha il Mean Prediction Error più prossimo a 0 (zero), l’RMS–standardized-prediction error più prossimo a 1, e RMSE e Average standard error più bassi è quella più verosimile.



