
Ad ogni release di ArcGIS Pro vengono introdotte diverse novità, tra le più interessanti rilasciate in una delle ultime versioni per l’Applicativo Desktop Esri (2.8) c’è la Data Engineering: una nuova modalità di gestione dati che incorpora alcune funzionalità già presenti con novità che permettono di eseguire operazioni di data processing.
Questa funzionalità è disponibile con tutti i livelli di licenza di ArcGIS Pro ed è compatibile sia con feature layer sia con tabelle non geometriche.
Vediamo più nello specifico in cosa consiste!
A cosa serve?
Le operazioni eseguibili con Data Engineering sono riassumibili in tre macrogruppi:
- l’esplorazione dei campi attraverso la visualizzazione di questi in una lista, nella quale è possibile visualizzare il data type, cambiare agilmente la simbologia del layer e creare grafici in modo tale da valutare la presenza di pattern sia spaziali che non;
- l’interazione con le statistiche ottenibili da ogni campo per valutarne la distribuzione;
- la preparazione dei dati attraverso processi di pulizia, costruzione, integrazione e formattazione.
Come utilizzarla?
Selezionato un dato nel Contents Pane è possibile aprire la Data Engineering in due modi differenti: dalla ribbon tab Data o dal menù che si apre cliccando il tasto destro. Attivato il comando si aprirà una finestra costituita a sua volta da due panel.
Nel panel di sinistra (Fields Panel) si ricollegano tutte le operazioni eseguibili nel macrogruppo 1 e 3 del paragrafo precedente, ossia è possibile esplorare i campi e preparare i dati. Nel panel di destra (Statistics Panel) sono invece associate le operazioni dei gruppi 2 e 3: l’interazione statistica e la preparazione dei dati.
Nell’immagine sottostante si può vedere un esempio di come si mostrano i panel per uno shapefile poligonale rappresentante l’impronta degli edifici.
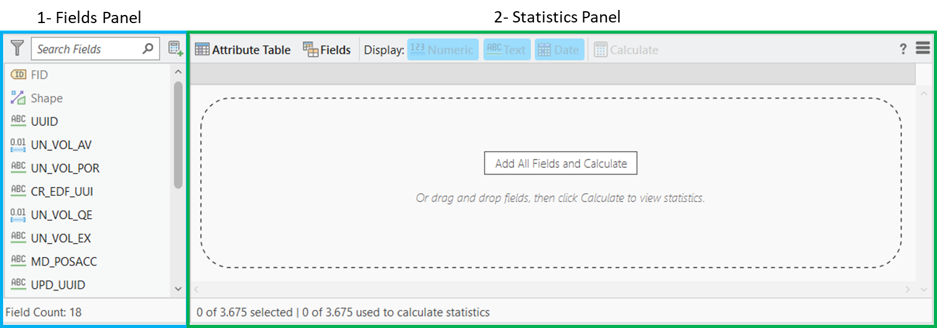
Fields Panel
Dal Fields Panel, oltre a valutare il data type del campo grazie all’icona presente di fianco al nome dello stesso, è possibile creare grafici e cambiare la simbologia del layer. Di default il tipo di grafico e il tipo di classificazione per la simbologia sono funzione del data type (es: per campi di testo si hanno grafici a barre e simbologia a valori univoci, per campi numerici istogrammi e simbologia a scala di colori graduata). Queste operazioni sono di aiuto nell’identificazione dei possibili valori attribuibili ad un campo permettendone una discriminazione qualitativa in tempi molto ridotti attraverso un semplice click. Come riportato nell’immagine sottostante, abbiamo provato ad applicare una simbologia basata sull’altezza degli edifici e creare un grafico del campo per comprenderne la distribuzione.

I grafici creati sono poi editabili ed esportabili; sono inoltre generabili anche in altri formati (boxplot, linee etc..) accendendo al menù che si apre con il tasto destro una volta selezionato un campo. Con lo stesso metodo è inoltre possibile creare grafici che permettono di analizzare due variabili contemporaneamente selezionando due campi, se questi sono di tipo numerico. Questa operazione permette di valutare la correlazione tra diverse variabili. Nell’immagine che segue abbiamo creato due grafici per valutare se ci fosse una relazione tra un campo e altri due. Uno dei due grafici consente di visualizzare la relazione tra l’altezza degli edifici e la loro area.
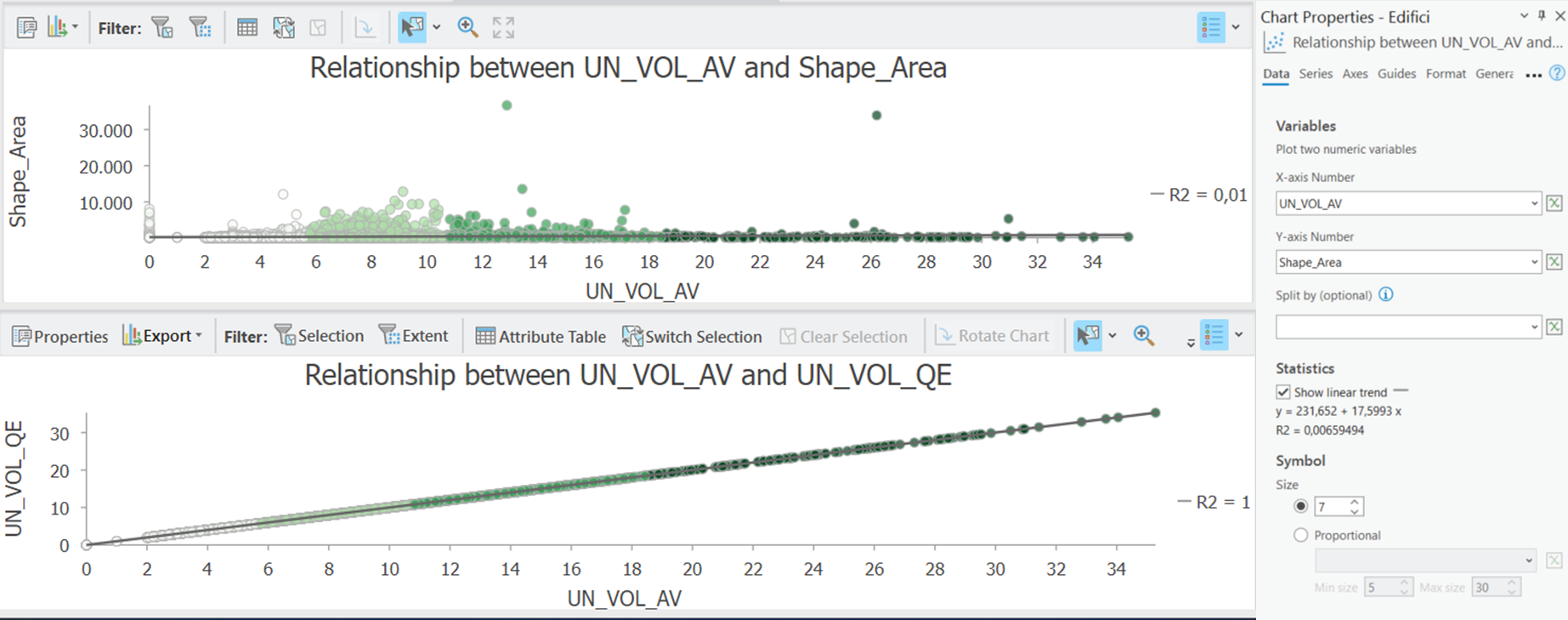
Statistics Panel
Dallo Statistics Panel è possibile valutare la qualità e la distribuzione dei valori per ogni campo. Selezionato uno, più o tutti i campi nel Fields Panel è possibile importarli in questa finestra e calcolarne le statistiche cliccando il Calculate button. Si possono poi filtrare i campi in base al data type selezionandoli e deselezionandoli dai pulsanti alla sinistra del Calculate button.
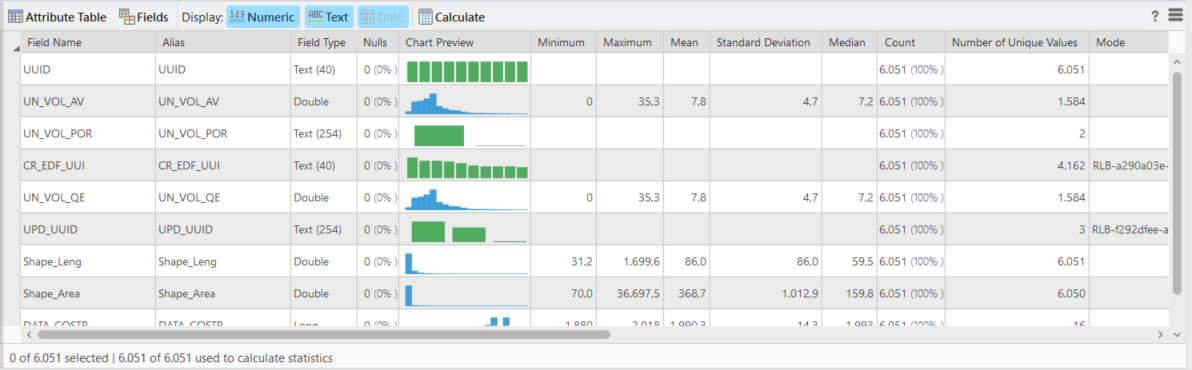
La tabella che ne deriva, contenente tutte le statistiche, è esportabile dal menù presente nel vertice in alto a destra del panel. Selezionando le singole celle della tabella, è inoltre possibile eseguire diverse operazioni come la selezione di feature che rispettano determinati criteri rispetto ad una certa statistica (come ad esempio tutti i valori sotto la media, tutti i valori ricadenti nella deviazione standard, il valore modale etc..) o eseguire operazioni legate alla preparazione del dato (vedi paragrafo successivo) come standardizzazione e/o trasformazione secondo diversi metodi e la creazione di nuovi campi tramite riclassificazione di quelli esistenti.
In figura è riportata una selezione eseguita per gli outliers del campo rappresentante l’altezza degli edifici, ovvero quei valori che risultano estremi e statisticamente non affidabili.
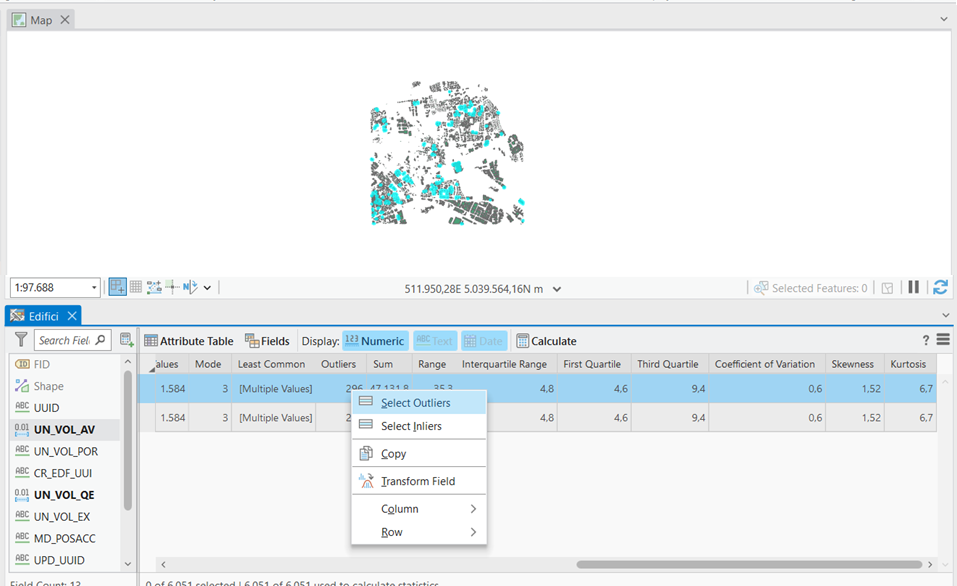
Preparazione dei dati
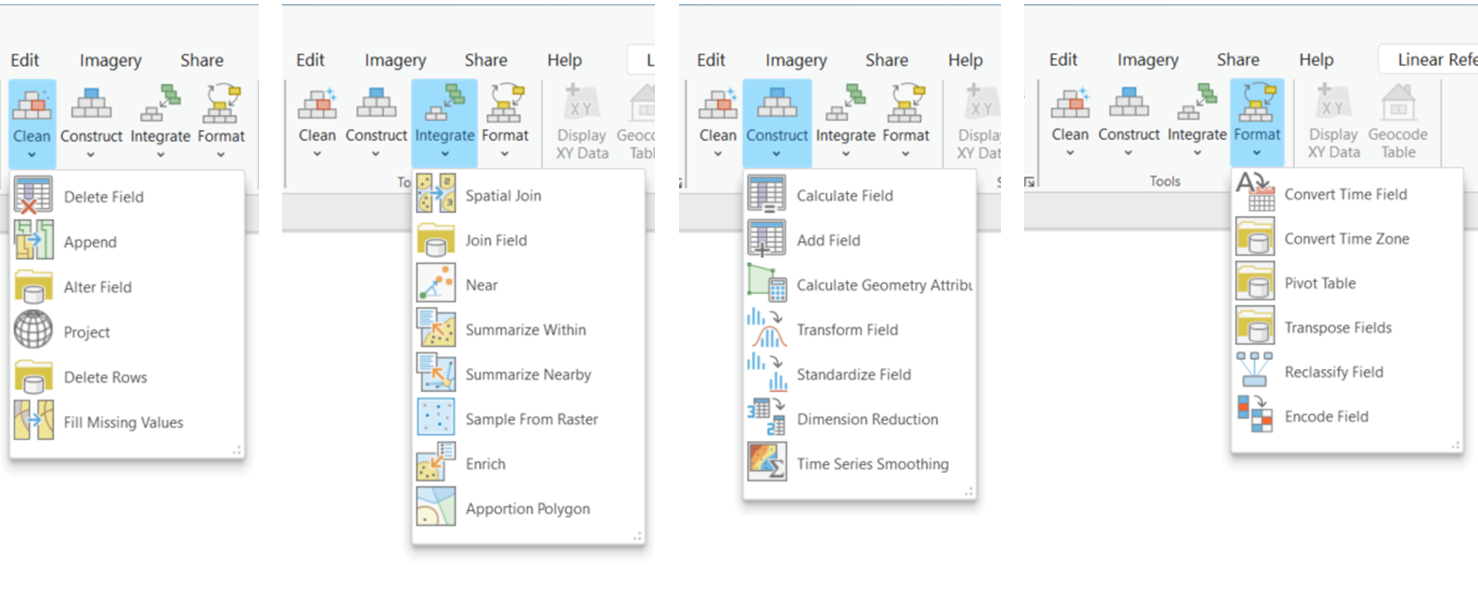
Le operazioni legate alla preparazione dei dati sono accessibili da entrambi i panel e dalla tab che si genera una volta attivata Data Engineering. I processi eseguibili in questa fase sono raggruppati in quattro classi:
- Clean, nel quale sono contenute operazioni come il cambio di nome di un campo, la cancellazione di righe, il riempimento di attributi nulli
- Construct, classe in cui sono contenute operazioni come l’aggiunta di campi, la riclassificazione e la standardizzazione
- Integrate, che comprende diverse operazioni di join, andando ad arricchire il dataset con nuovi dati
- Format, che permette di cambiare la codifica dei campi.

Tra le operazioni accessibili da questi gruppi ci sono funzioni note e meno note. Le più comuni sono sicuramente operazioni come il Join/Spatial-Join, il Calculate Field/Geometry e l’Add/Delete Field. Funzioni meno note ma decisamente utili sono: Transform Field che permette di trasformare la distribuzione dei valori di un campo in una distribuzione normale, Standardize Field che permette di standardizzare rispetto ad un valore minimo ed uno massimo un campo e Dimension Reduction che permette di diminuire il numero dei campi di una tabella attributi cercando la correlazione tra le variabili indicate creando nuovi campi in sostituzione dei vecchi.
Ci sono poi molte altre funzioni, come quella che permette di costruire una tabella Pivot o di sostituire i valori nulli, che potrebbero risultare molto utili in diversi tipi di analisi. Per approfondire tutte le operazioni racchiuse e raggruppate nella Data Engineering Tab per la preparazione del dato si rimanda alla documentazione Esri.
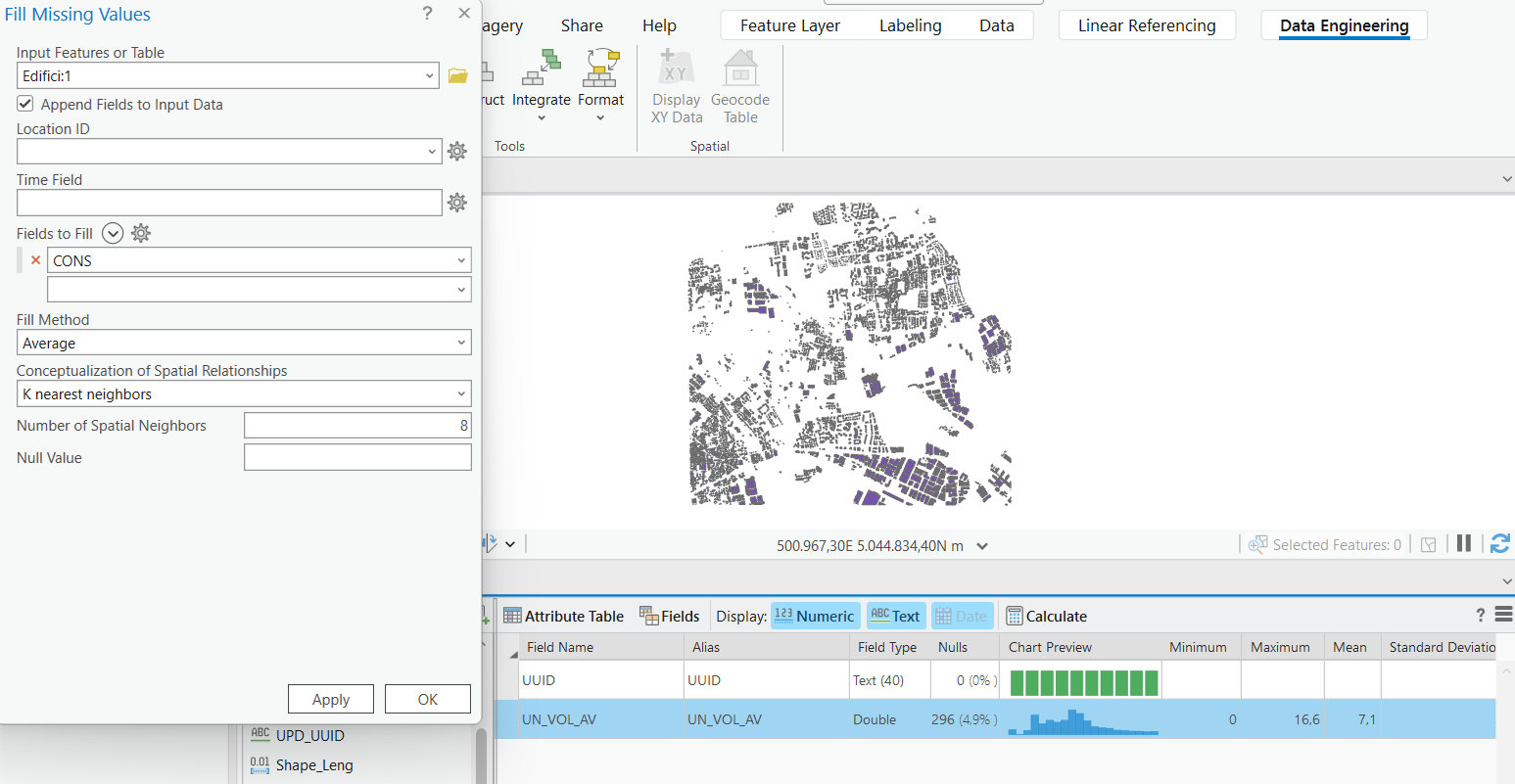
Di seguito è riportato un esempio di calcolo per il riempimento di valori nulli di un campo attraverso uno dei comandi per la preparazione dei dati.
Conclusioni
In questo articolo abbiamo visto alcune delle principali funzionalità disponibili nella Tab Data Engineering. Nei casi più comuni la possiamo usare per:
- valutare la bontà dei nostri dati in base a statistiche e alla presenza di attributi nulli
- stimare la correlazione tra variabili di una tabella attributi
- valutare se gli attributi di un campo sono univoci, continui o categorizzati attraverso grafici e simbologia in modo rapido
Un esempio di un possibile utilizzo della Data engineering è riportato a questo link.
Questa è una delle tante novità rilasciate ultimamente da ESRI, puoi controllare il nostro articolo sulla release della versione 3.1 dell’applicativo desktop per non perderti le ultimissime.
Per maggiori informazioni sul mondo Esri contatta lo staff GIS di One Team via mail scrivendo a gis@oneteam.it o chiamaci allo 0247719331.
Iscriviti al blog per non perderti i prossimi appuntamenti e visita il nostro canale Youtube dove puoi trovare una playlist dedicata al GIS!




